This article will guide you how to use Apache Drill REST API interface to query HIVE data. We will say how hive can be queries but the same approach can be used to query data from Hbase, MongoDB , flat file etc
PreRequisite:
1. Apache Hadoop should be installed.
2. Apache Hive should be installed.
3. Apache Drill is installed.
Implementation:
1. Goto the path where hive is installed.

2. Start the hive Metastore service.

3. Start a new terminal and goto path where Apache Drill is installed

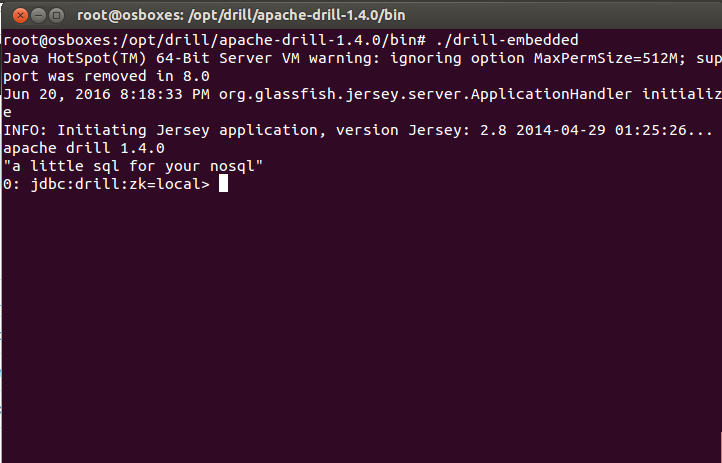
4. Start the drill service in embeded mode.










Sourabh Jain
Big Data & Analytics Architect
PreRequisite:
1. Apache Hadoop should be installed.
2. Apache Hive should be installed.
3. Apache Drill is installed.
Implementation:
1. Goto the path where hive is installed.

2. Start the hive Metastore service.

3. Start a new terminal and goto path where Apache Drill is installed

4. Start the drill service in embeded mode.

5. Open Web-browser and goto localhost:8047

:
6. Goto Storage tab and enable hive storage plugin

7. Click on update against the hive storage plugin and change the values as shown below:

8. Lets fire a query on the hive tables now. We have a transaction_orc table in hive and a store table. We want to find the total sales across each store.

9. Now we will look to fire the same query via a REST API.
10. Open a Web browser with any REST API client. We will user Firefox with the REST Client plugin.

11. Select the method as "POST" , URL as "http://localhost:8047/query.json" , Header as "Content-Type":"application/json"

12. In the body section paste the json as shown below:

13. Now click on send button and validate the response.


14. As seen we have got the result in the json format. We can use this approach using any REST API programming framework,parse the data and display the data on the UI.
Conclusion:
Hope this helps you to understand how to configure Apache Drill and use REST API to query dataSourabh Jain
Big Data & Analytics Architect